> ## Documentation Index
> Fetch the complete documentation index at: https://docs.runcomfy.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Codes
When an API call fails, RunComfy returns an HTTP error status and a JSON body that may include an `error_code` and message.
This page lists error codes you may see when calling the **Trainer API**, including **datasets** (create/upload/processing) and **AI Toolkit training jobs** (submit/status/result).
If you haven't yet, start with:
* **[Trainer API Quickstart](/trainer-apis/quickstart)**
* **[Training Datasets API](/trainer-apis/async-queue-endpoints-datasets)**
* **[Training Jobs API](/trainer-apis/async-queue-endpoints-training-jobs)**
***
## Error code structure
Trainer API error codes follow a consistent numeric pattern:
* The **first 3 digits** match the HTTP status (e.g. `400xx`, `422xx`, `500xx`).
* The **last 2 digits** are a resource-specific sequence:
* **`01–49`**: Dataset errors
* **`51–99`**: Job errors
***
## Dataset API error codes
Applies to endpoints under `/prod/v1/trainers/datasets` (create/upload/status/list/delete).
### 40001 INVALID\_DATASET\_ID
**Meaning:** The supplied dataset identifier is not a valid UUID.
**Where you may see it:** Any endpoint that takes `{dataset_id}` in the URL path.
**What to try:**
* Use the exact `id` returned by `POST /prod/v1/trainers/datasets` (or listed by `GET /prod/v1/trainers/datasets`).
* Make sure you didn’t accidentally pass a dataset **name** where a dataset **id** is required.
***
### 40401 DATASET\_NOT\_FOUND
**Meaning:** Dataset does not exist, was deleted, or is not owned by the caller.
**Where you may see it:** Any endpoint that takes `{dataset_id}` in the URL path.
**What to try:**
* Confirm the dataset exists by calling `GET /prod/v1/trainers/datasets`.
* Make sure you are using the token for the account that owns the dataset.
* If you recently deleted the dataset, create a new dataset and upload again.
***
### 40901 DATASET\_NAME\_CONFLICT
**Meaning:** A non-deleted dataset with the same name already exists for the user.
**Where you may see it:** `POST /prod/v1/trainers/datasets`
**What to try:**
* Pick a **unique** dataset name, or omit `name` and let RunComfy generate one (e.g. `ds_...`).
* If you intended to reuse an existing dataset, call `GET /prod/v1/trainers/datasets` to find its `id` and `name`.
***
### 42201 INVALID\_DATASET\_NAME
**Meaning:** Dataset name contains invalid characters.
**Where you may see it:** `POST /prod/v1/trainers/datasets`
**What to try:**
* Avoid spaces and special characters in dataset names.
* Use a simple name with letters/numbers (and optionally `_` / `-`).
***
### 42202 INVALID\_FILE\_TYPE
**Meaning:** The file extension is not in the list of supported dataset formats.
**Where you may see it:** `POST /prod/v1/trainers/datasets/{dataset_id}/upload` and `POST /prod/v1/trainers/datasets/{dataset_id}/get-upload-endpoint`
**What to try:**
* Upload supported dataset file types (images/videos) plus optional caption `.txt` files.
* Ensure captions follow the pairing rule: `img_0001.jpg` ↔ `img_0001.txt`, `clip_0001.mp4` ↔ `clip_0001.txt`.
***
### 42203 FILE\_SIZE\_EXCEEDED
**Meaning:** File exceeds the 150 MB direct-upload limit.
**Where you may see it:** `POST /prod/v1/trainers/datasets/{dataset_id}/upload`
**What to try:**
* For direct upload, keep each file **≤150MB** (150,000,000 bytes).
* For files **>150MB**, use signed URLs: `POST /prod/v1/trainers/datasets/{dataset_id}/get-upload-endpoint` then `PUT` bytes to `upload_url`.
***
### 42204 UPLOAD\_TO\_FAILED\_DATASET
**Meaning:** Upload rejected because the dataset is in `FAILED` status.
**Where you may see it:** `POST /prod/v1/trainers/datasets/{dataset_id}/upload` and `POST /prod/v1/trainers/datasets/{dataset_id}/get-upload-endpoint`
**What to try:**
* Check dataset status via `GET /prod/v1/trainers/datasets/{dataset_id}/status` and inspect the `error` field.
* Fix the underlying issue, then **create a new dataset** and re-upload files (recommended).
***
### 42205 EMPTY\_FILE\_LIST
**Meaning:** The `filenameToByteSize` map in the request body is empty.
**Where you may see it:** `POST /prod/v1/trainers/datasets/{dataset_id}/get-upload-endpoint`
**What to try:**
* Provide a **non-empty** `filenameToByteSize` map (each filename mapped to its exact byte size).
* If you meant to direct-upload a single file, use `POST /prod/v1/trainers/datasets/{dataset_id}/upload` with a `file` form field.
***
### 50001 DATASET\_INTERNAL\_ERROR
**Meaning:** Unexpected internal error not matching another category.
**What to try:**
* Retry the request after a short delay.
* If it repeats, contact support with the full error response and your `dataset_id`.
***
### 50002 UPLOAD\_IO\_ERROR
**Meaning:** File write to the storage backend failed.
**Where you may see it:** `POST /prod/v1/trainers/datasets/{dataset_id}/upload`
**What to try:**
* Retry the upload (preferably with backoff) and ensure your network is stable.
* If you continue to see this error, try signed URL uploads instead (see the Datasets API doc).
***
### 50003 STORAGE\_SCAN\_ERROR
**Meaning:** Failed to scan / list the dataset directory on disk.
**Where you may see it:** `GET /prod/v1/trainers/datasets/{dataset_id}/status`
**What to try:**
* Confirm every upload completed successfully (direct upload response, or signed URL `PUT` returning 200/204).
* Re-upload the problematic files (or create a new dataset and upload again).
* If the issue persists, capture the full error response and contact support.
***
### 50004 DATASET\_PROCESSING\_FAILED
**Meaning:** Generic dataset processing failure (fallback for legacy records).
**What to try:**
* Check `GET /prod/v1/trainers/datasets/{dataset_id}/status` for the dataset `error` details.
* Verify dataset rules (supported file types + caption pairing by **same base filename**).
* Re-upload after fixing the files (or create a new dataset and upload again), then poll until `READY`.
***
## Training Jobs (AI Toolkit) API error codes
Applies to endpoints under `/prod/v1/trainers/ai-toolkit/jobs` (submit/status/result/cancel/resume/edit).
### 40051 INVALID\_JOB\_ID
**Meaning:** Job identifier is not a valid UUID.
**Where you may see it:** Any endpoint that takes `{job_id}` in the URL path.
**What to try:**
* Use the exact `job_id` returned by `POST /prod/v1/trainers/ai-toolkit/jobs`.
* Double-check you didn’t paste a different identifier (for example a dataset id) into the job path.
***
### 40451 JOB\_NOT\_FOUND
**Meaning:** Job does not exist, was deleted, or is not owned by the caller.
**Where you may see it:** Any endpoint that takes `{job_id}` in the URL path.
**What to try:**
* Confirm you’re using the correct token (the job must belong to the authenticated account).
* Re-submit the training job if the original job was deleted or never created successfully.
***
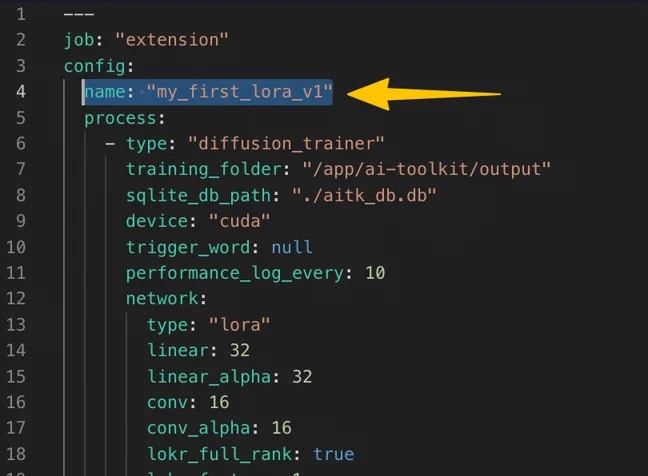
### 40951 JOB\_NAME\_CONFLICT
**Meaning:** Job name already exists for this user.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Pick a unique job name in your YAML config (commonly `config.name`, and/or `meta.name`).
***
### 42251 INVALID\_CONFIG\_FORMAT
**Meaning:** `config_file_format` must be `yaml`.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Set `"config_file_format": "yaml"` in the request body.
***
### 42252 INVALID\_GPU\_TYPE
**Meaning:** `gpu_type` is not a supported value.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Use one of the supported `gpu_type` values listed in **[Training Jobs API](/trainer-apis/async-queue-endpoints-training-jobs#request-body-important-fields)**.
***
### 42253 INVALID\_YAML
**Meaning:** `config_file` is not valid YAML.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Validate the YAML locally before submitting.
* Make sure the JSON request body contains `config_file` as a **string** (your YAML must be JSON-escaped).
***
### 42254 DATASET\_NOT\_FOUND
**Meaning:** Dataset referenced in config was not found.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Make sure your YAML references the correct `{dataset_name}` (the dataset’s `name`, not its `id`).
* Confirm the dataset exists via `GET /prod/v1/trainers/datasets`.
***
### 42255 DATASET\_NOT\_READY
**Meaning:** Dataset referenced in config is not in `READY` status.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Poll `GET /prod/v1/trainers/datasets/{dataset_id}/status` until `READY`.
* If the dataset is `FAILED`, inspect `error`, fix the issue, then create a new dataset and upload again.
***
### 42256 NO\_TRAINING\_DATA
**Meaning:** Dataset has no usable training files.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Ensure the dataset contains at least one supported image/video file (and any optional captions).
* Re-upload after fixing file types/paths, then wait for dataset `READY`.
***
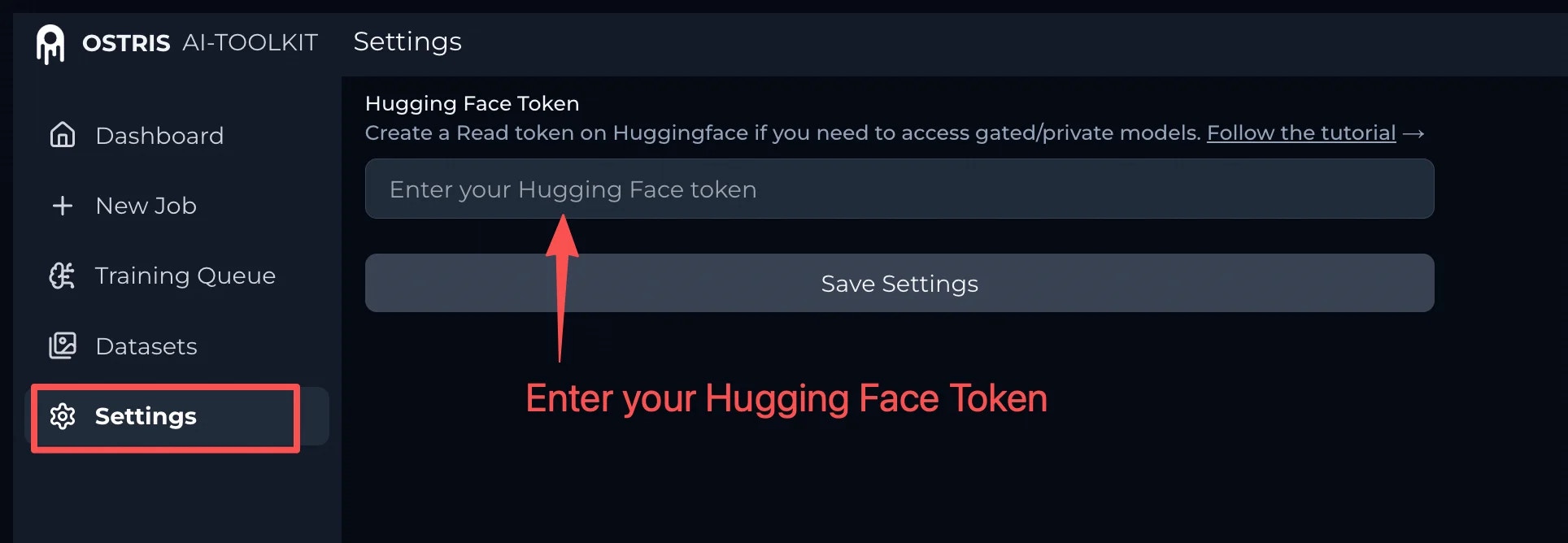
### 42257 FLUX\_HF\_TOKEN\_REQUIRED
**Meaning:** FLUX model training requires a Hugging Face token.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Provide a valid Hugging Face token (with **read access**) in the way your training config expects (for example via a config field or secret).
* Make sure the Hugging Face **model repo is authorized for your account** (many FLUX repos are gated: you must request/accept access on Hugging Face, and your token must be able to read that repo).
* Follow the step-by-step guide here: **[How to set up a Hugging Face token for FLUX training](https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit)**.
 ***
### 42258 FLUX2\_OOM\_RISK
**Meaning:** FLUX.2 training settings have a high out-of-memory (OOM) risk.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Reduce `batch_size` and/or reduce resolution (`max_res`).
* As a rule of thumb, this error is raised when (batch\_size \times (max\_res/1024)^2 \ge 6).
***
### 42259 QWEN\_EDIT\_CONTROL\_MISSING
**Meaning:** Qwen Edit requires control images in the dataset.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* In the config\_file, add the required control images to your dataset (and re-upload), then wait for dataset `READY` and retry job submission.
***
### 42260 QWEN\_EDIT\_SAMPLE\_CONTROL\_MISSING
**Meaning:** Qwen Edit requires control images in sample prompts.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* In the config\_file, update your sample configuration so each sample prompt includes the required control image(s).
***
### 42258 FLUX2\_OOM\_RISK
**Meaning:** FLUX.2 training settings have a high out-of-memory (OOM) risk.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Reduce `batch_size` and/or reduce resolution (`max_res`).
* As a rule of thumb, this error is raised when (batch\_size \times (max\_res/1024)^2 \ge 6).
***
### 42259 QWEN\_EDIT\_CONTROL\_MISSING
**Meaning:** Qwen Edit requires control images in the dataset.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* In the config\_file, add the required control images to your dataset (and re-upload), then wait for dataset `READY` and retry job submission.
***
### 42260 QWEN\_EDIT\_SAMPLE\_CONTROL\_MISSING
**Meaning:** Qwen Edit requires control images in sample prompts.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* In the config\_file, update your sample configuration so each sample prompt includes the required control image(s).
 ***
### 42261 WAN\_I2V\_SAMPLING\_CRASH
**Meaning:** Missing Control Image in Samples. Your sample prompts are missing a **Control Image**. I2V sampling requires both a prompt and a control image for each sample. If a Control Image is missing, sampling may fail and training can stop early.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Add a **Control Image** for every sample prompt in **Samples** in your config\_file.
***
### 42262 INVALID\_JOB\_NAME
**Meaning:** Job name contains invalid characters.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* In the config\_file, update the job name in your YAML (commonly `config.name`) to avoid spaces and special characters.
***
### 42261 WAN\_I2V\_SAMPLING\_CRASH
**Meaning:** Missing Control Image in Samples. Your sample prompts are missing a **Control Image**. I2V sampling requires both a prompt and a control image for each sample. If a Control Image is missing, sampling may fail and training can stop early.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Add a **Control Image** for every sample prompt in **Samples** in your config\_file.
***
### 42262 INVALID\_JOB\_NAME
**Meaning:** Job name contains invalid characters.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* In the config\_file, update the job name in your YAML (commonly `config.name`) to avoid spaces and special characters.
 ***
### 42263 MULTI\_FRAME\_LATENT\_CACHING
**Meaning:** `num_frames > 1` together with `cache_latents_to_disk` is not supported.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* If you need multi-frame training, disable latent caching to disk.
* If you need latent caching, set `num_frames: 1`.
***
### 42264 DIFF\_OUTPUT\_PRESERVATION\_TRIGGER
**Meaning:** `diff_output_preservation` is enabled but `trigger_word` is missing.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Set `trigger_word` when enabling `diff_output_preservation`, then resubmit.
***
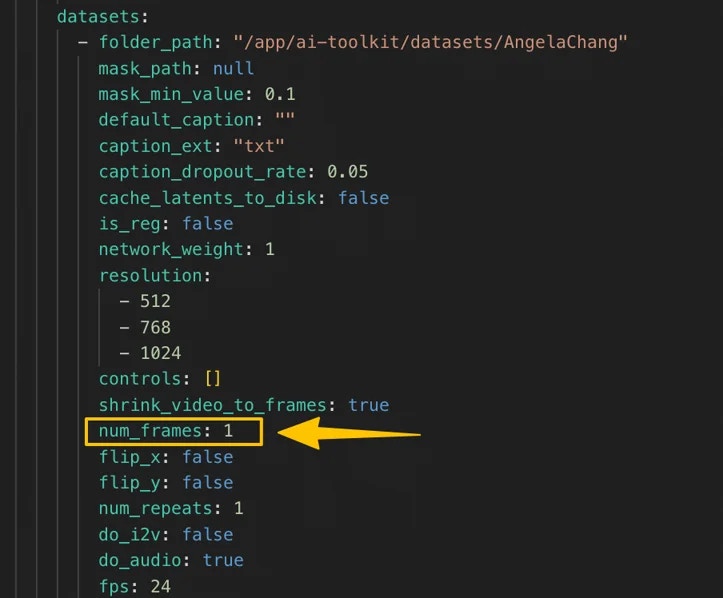
### 42265 VIDEO\_LORA\_NUM\_FRAMES\_ONE
**Meaning:** Your dataset contains **video samples**, but your training job's config\_file is configured with `num_frames = 1`. With video data and `num_frames = 1`, AI Toolkit can’t correctly locate and load the training frames, so the job is very likely to fail.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Set **Num Frames** to a value **greater than 1** (for example `41` or `81`), then resubmit the job.
* Double-check the dataset referenced by your config `folder_path` contains video files (or video + caption `.txt` files) and that your `num_frames` matches the dataset type.
***
### 42263 MULTI\_FRAME\_LATENT\_CACHING
**Meaning:** `num_frames > 1` together with `cache_latents_to_disk` is not supported.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* If you need multi-frame training, disable latent caching to disk.
* If you need latent caching, set `num_frames: 1`.
***
### 42264 DIFF\_OUTPUT\_PRESERVATION\_TRIGGER
**Meaning:** `diff_output_preservation` is enabled but `trigger_word` is missing.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Set `trigger_word` when enabling `diff_output_preservation`, then resubmit.
***
### 42265 VIDEO\_LORA\_NUM\_FRAMES\_ONE
**Meaning:** Your dataset contains **video samples**, but your training job's config\_file is configured with `num_frames = 1`. With video data and `num_frames = 1`, AI Toolkit can’t correctly locate and load the training frames, so the job is very likely to fail.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Set **Num Frames** to a value **greater than 1** (for example `41` or `81`), then resubmit the job.
* Double-check the dataset referenced by your config `folder_path` contains video files (or video + caption `.txt` files) and that your `num_frames` matches the dataset type.
 ***
### 42266 IMAGE\_DATASET\_MULTI\_FRAMES
**Meaning:** Image-only dataset is being used with `num_frames > 1`.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* If your dataset contains only images, set `num_frames: 1`.
***
### 42267 INVALID\_RESUME\_STATE
**Meaning:** Job can only be resumed when it is `STOPPED` (or `CANCELED`).
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/resume`
**What to try:**
* Check the job status via `GET /prod/v1/trainers/ai-toolkit/jobs/{job_id}/status`.
* Only call `resume` after the job transitions to `STOPPED` (or `CANCELED`).
***
### 42268 LTX2\_VIDEO\_I2V\_BATCH\_SIZE
**Meaning:** LTX2 with video (`num_frames > 1`) or I2V (`do_i2v = true`) requires `batch_size = 1`.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Set `train.batch_size` to `1` when training LTX2 with video data or I2V mode.
* Current `batch_size > 1` will cause a tensor shape mismatch at training start.
***
### 42269 DIFF\_PRESERVATION\_CACHE\_CONFLICT
**Meaning:** `diff_output_preservation` and `cache_text_embeddings` cannot both be enabled at the same time.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Disable one of them before starting training: either turn off `diff_output_preservation` or turn off `cache_text_embeddings`.
***
### 42270 IMAGE\_MODEL\_GC\_OFF\_OOM\_RISK
**Meaning:** Large image model with `gradient_checkpointing: false` has very high out-of-memory (OOM) risk.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Turn ON Gradient Checkpointing (`train.gradient_checkpointing: true`) in your config.
***
### 42271 FLUX\_HIGH\_BATCH\_OOM\_RISK
**Meaning:** FLUX.1-dev with `batch_size >= 8` has high OOM risk even with gradient checkpointing enabled.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Set `batch_size` to 1–4 and increase `gradient_accumulation` to compensate.
***
### 42272 WAN\_VIDEO\_OOM\_RISK
**Meaning:** Wan2.2 14B with 81+ frames at high resolution or batch\_size risks OOM.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Reduce `num_frames` below 81, lower resolution, or set `batch_size` to `1`.
***
### 42273 INVALID\_GPU\_COUNT
**Meaning:** `gpu_count` must be `1` or `8`, and multi-GPU (`8`) is only supported for H100 (`ADA_80_PLUS`).
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Use `gpu_count: 1` (default, single GPU) or `gpu_count: 8` (multi-GPU, H100 only).
* If you need multi-GPU training, set `gpu_type` to `ADA_80_PLUS` (H100).
***
### 42274 INVALID\_LEARNING\_RATE
**Meaning:** Learning rate (`train.lr`) is missing, non-numeric, or not positive.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Set `train.lr` to a valid positive number (e.g. `1e-4`).
***
### 42275 MISSING\_MODEL\_ARCH
**Meaning:** `config.process[0].model.arch` is required but missing.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Add the `model.arch` field to your config. Supported values include `flux`, `wan` for Wan2.1/2.2, `ltx2` for LTX2, `sdxl` for SDXL, `zimage:turbo` for Z-Image-Turbo, etc.
***
### 42276 INVALID\_EDIT\_STATE
**Meaning:** Job can only be edited when it is not active (`STOPPED`, `CANCELED`, or `FAILED`).
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Check the job status via `GET /prod/v1/trainers/ai-toolkit/jobs/{job_id}/status`.
* If the job is `IN_QUEUE` or `RUNNING`, cancel it first with `POST .../cancel`, then edit.
***
### 42277 CONFIG\_NAME\_IMMUTABLE
**Meaning:** `config.name` cannot be changed via edit; it must match the original job name.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Keep the same `config.name` (and/or `meta.name`) as the original job when editing.
* If you need a different name, submit a new job instead.
***
### 50051 JOB\_INTERNAL\_ERROR
**Meaning:** Unexpected internal error.
**What to try:**
* Retry after a short delay.
* If it repeats, contact support with the full error response and your `job_id`.
***
### 50052 JOB\_CREATE\_FAILED
**Meaning:** Failed to create the job record in the database.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Retry job submission once.
* If it repeats, contact support with the full error response and your request payload.
## Getting help
If you hit an error not listed here, contact [hi@runcomfy.com](mailto:hi@runcomfy.com) with the full error response plus your `dataset_id` (and `job_id` if applicable).
***
### 42266 IMAGE\_DATASET\_MULTI\_FRAMES
**Meaning:** Image-only dataset is being used with `num_frames > 1`.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* If your dataset contains only images, set `num_frames: 1`.
***
### 42267 INVALID\_RESUME\_STATE
**Meaning:** Job can only be resumed when it is `STOPPED` (or `CANCELED`).
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/resume`
**What to try:**
* Check the job status via `GET /prod/v1/trainers/ai-toolkit/jobs/{job_id}/status`.
* Only call `resume` after the job transitions to `STOPPED` (or `CANCELED`).
***
### 42268 LTX2\_VIDEO\_I2V\_BATCH\_SIZE
**Meaning:** LTX2 with video (`num_frames > 1`) or I2V (`do_i2v = true`) requires `batch_size = 1`.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Set `train.batch_size` to `1` when training LTX2 with video data or I2V mode.
* Current `batch_size > 1` will cause a tensor shape mismatch at training start.
***
### 42269 DIFF\_PRESERVATION\_CACHE\_CONFLICT
**Meaning:** `diff_output_preservation` and `cache_text_embeddings` cannot both be enabled at the same time.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Disable one of them before starting training: either turn off `diff_output_preservation` or turn off `cache_text_embeddings`.
***
### 42270 IMAGE\_MODEL\_GC\_OFF\_OOM\_RISK
**Meaning:** Large image model with `gradient_checkpointing: false` has very high out-of-memory (OOM) risk.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Turn ON Gradient Checkpointing (`train.gradient_checkpointing: true`) in your config.
***
### 42271 FLUX\_HIGH\_BATCH\_OOM\_RISK
**Meaning:** FLUX.1-dev with `batch_size >= 8` has high OOM risk even with gradient checkpointing enabled.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Set `batch_size` to 1–4 and increase `gradient_accumulation` to compensate.
***
### 42272 WAN\_VIDEO\_OOM\_RISK
**Meaning:** Wan2.2 14B with 81+ frames at high resolution or batch\_size risks OOM.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Reduce `num_frames` below 81, lower resolution, or set `batch_size` to `1`.
***
### 42273 INVALID\_GPU\_COUNT
**Meaning:** `gpu_count` must be `1` or `8`, and multi-GPU (`8`) is only supported for H100 (`ADA_80_PLUS`).
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Use `gpu_count: 1` (default, single GPU) or `gpu_count: 8` (multi-GPU, H100 only).
* If you need multi-GPU training, set `gpu_type` to `ADA_80_PLUS` (H100).
***
### 42274 INVALID\_LEARNING\_RATE
**Meaning:** Learning rate (`train.lr`) is missing, non-numeric, or not positive.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Set `train.lr` to a valid positive number (e.g. `1e-4`).
***
### 42275 MISSING\_MODEL\_ARCH
**Meaning:** `config.process[0].model.arch` is required but missing.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs` and `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Add the `model.arch` field to your config. Supported values include `flux`, `wan` for Wan2.1/2.2, `ltx2` for LTX2, `sdxl` for SDXL, `zimage:turbo` for Z-Image-Turbo, etc.
***
### 42276 INVALID\_EDIT\_STATE
**Meaning:** Job can only be edited when it is not active (`STOPPED`, `CANCELED`, or `FAILED`).
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Check the job status via `GET /prod/v1/trainers/ai-toolkit/jobs/{job_id}/status`.
* If the job is `IN_QUEUE` or `RUNNING`, cancel it first with `POST .../cancel`, then edit.
***
### 42277 CONFIG\_NAME\_IMMUTABLE
**Meaning:** `config.name` cannot be changed via edit; it must match the original job name.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs/{job_id}/edit`
**What to try:**
* Keep the same `config.name` (and/or `meta.name`) as the original job when editing.
* If you need a different name, submit a new job instead.
***
### 50051 JOB\_INTERNAL\_ERROR
**Meaning:** Unexpected internal error.
**What to try:**
* Retry after a short delay.
* If it repeats, contact support with the full error response and your `job_id`.
***
### 50052 JOB\_CREATE\_FAILED
**Meaning:** Failed to create the job record in the database.
**Where you may see it:** `POST /prod/v1/trainers/ai-toolkit/jobs`
**What to try:**
* Retry job submission once.
* If it repeats, contact support with the full error response and your request payload.
## Getting help
If you hit an error not listed here, contact [hi@runcomfy.com](mailto:hi@runcomfy.com) with the full error response plus your `dataset_id` (and `job_id` if applicable).