request_id immediately, then poll status and fetch results when the run completes.
You can use the same endpoints for two sources:
- Models catalog: run any prebuilt model from Models by calling its
model_id. - Trainer LoRA inference (no deployment): run inference for a LoRA trained (or imported) in RunComfy Trainer by calling the same Model API endpoints with the
model_idof the LoRA’s base model (copy it from the base model’s model page), and pass the LoRA as an input parameter (see LoRA Inputs (Trainer)).
Endpoints
Base URL:https://model-api.runcomfy.net
| Endpoint | Method | Purpose |
|---|---|---|
/v1/models/{model_id} | POST | Submit an asynchronous request |
/v1/requests/{request_id}/status | GET | Check request status |
/v1/requests/{request_id}/result | GET | Retrieve request result |
/v1/requests/{request_id}/cancel | POST | Cancel a queued request |
Common Path Parameters
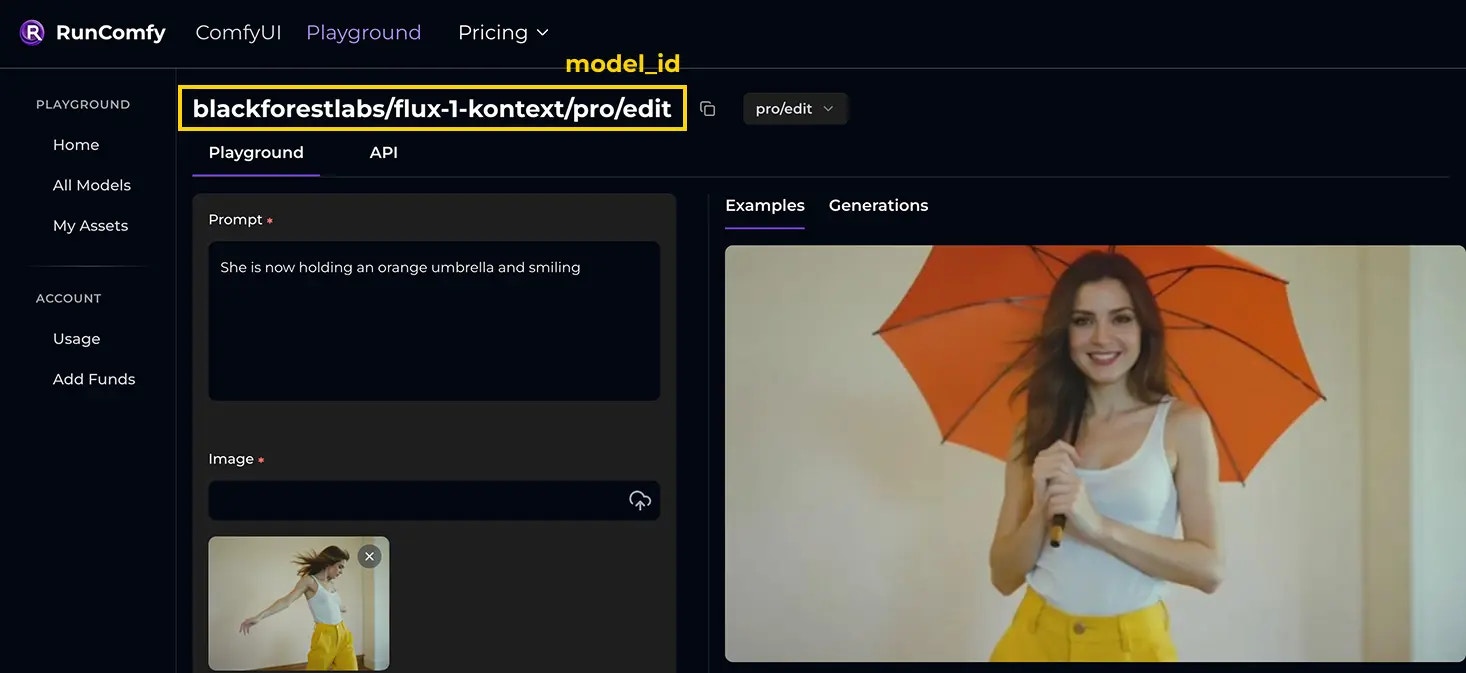
model_id string (required). The identifier of the model/pipeline you want to run (e.g., blackforestlabs/flux-1-kontext/pro/edit).
- For Models catalog usage, pick a model from Models. Each model page shows its
model_id. - For Trainer usage, in Trainer > Run LoRA select your LoRA’s base model, then open that base model page and copy its
model_id(thismodel_idrepresents the inference pipeline you’ll run via the Model API).
request_id string (required for non‑submit endpoints). Returned by POST /v1/models/{model_id}; use it to check status, fetch result, or cancel.
Submit a Request
Submit an asynchronous request to a model. Returns arequest_id and convenience URLs to poll and fetch results.
Request Example
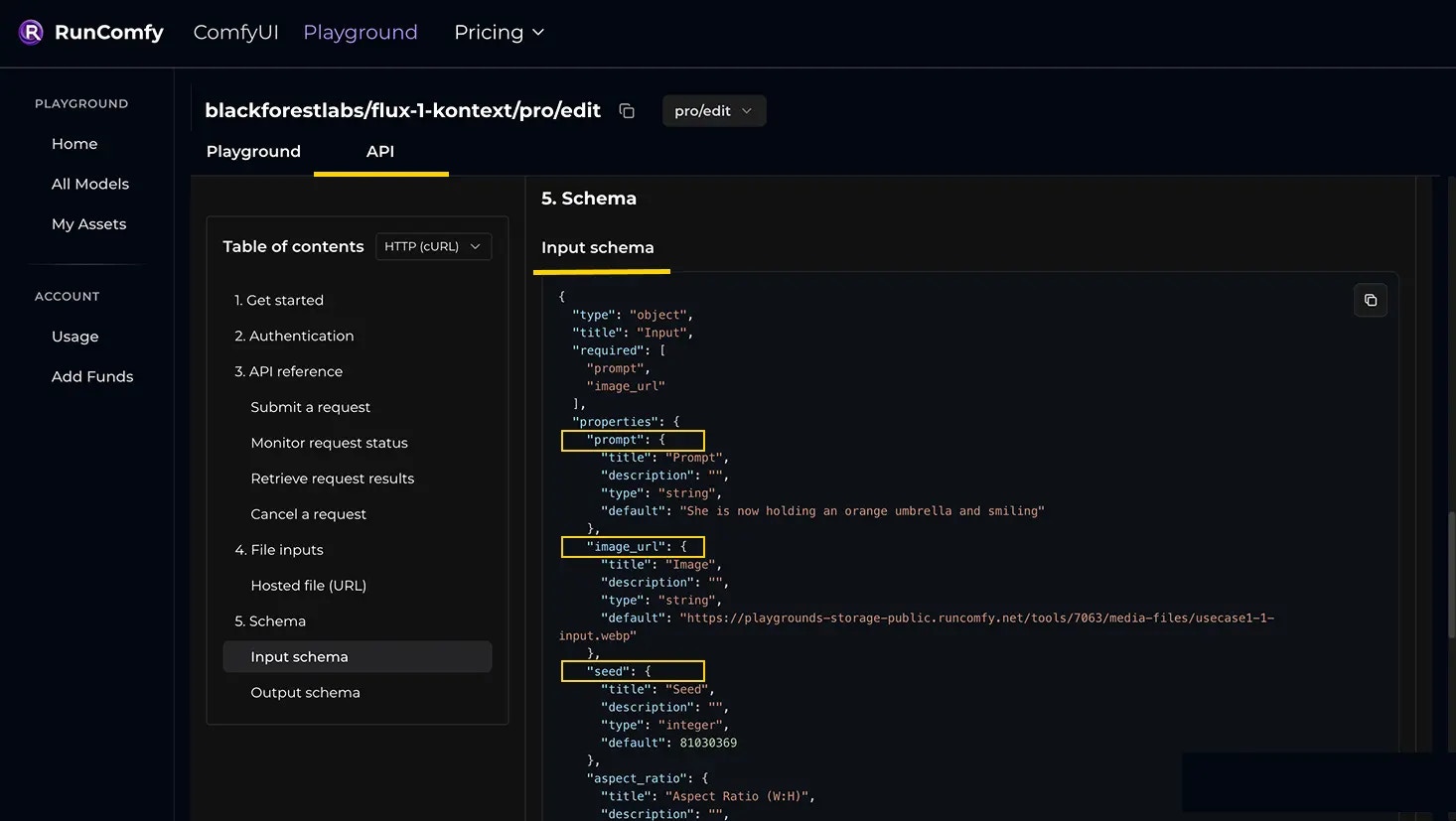
Example using the blackforestlabs/flux-1-kontext/pro/edit model:prompt, image_url, seed, aspect_ratio) map 1:1 to this model’s Input schema. See the model’s API page for required fields, types, enums, and defaults. For reference, see the Input schema on the blackforestlabs/flux-1-kontext/pro/edit API page.
Response Example
request_id(string): Unique identifier for the request.status_url(string): URL to poll for request progress.result_url(string): URL to fetch outputs once the request completes.cancel_url(string): URL to cancel the request if still queued.
Monitor Request Status
Poll the current state for arequest_id. Typical states are: in_queue > in_progress > completed (or cancelled).
Request Example
Response Example
status(string): States while polling:in_queue,in_progress,completed,cancelled.status_url(string): URL to poll for request progress.result_url(string): URL to fetch outputs once the request completes.- For
in_queue,queue_position(integer): Your position in the queue.
Retrieve Request Results
Whenstatus is completed, fetch the final outputs. The shape of result (single URI vs. object/array) is defined by the model’s Output schema on its API page.
Request Example
Response Example
status(string): One ofsucceeded,failed,in_queue,in_progress, orcancelled.output(varies by model): the response body defined by the model’s Output schema (often URLs to generated assets).created_at(string): When the request was created.finished_at(string): When the request completed.
Cancel a Request
Cancel a request that is still queued. Already completed or terminated requests will be no‑ops.Request Example
Response Example
outcome(string):cancelledif the cancellation is accepted;not_cancellableif the request is already in progress or completed.
Image/Video/Audio Inputs
Use a publicly accessible HTTPS URL that returns the file with an unauthenticated GET request (no cookies or auth headers). Prefer stable or pre‑signed URLs for private assets.LoRA Inputs (Trainer)
This section applies to LoRA inference. If you’re not deploying your LoRA as a dedicated endpoint, you can run it directly via the Model API. In this flow, the Model API works the same way as for the Models catalog (same base URL and endpoints). The key differences are:- Your
model_idrepresents the inference pipeline you’ll run via the Model API (in Trainer > Run LoRA, select your LoRA’s base model, then open that base model page and copy itsmodel_id). - The LoRA is provided via input parameters in the request body (your payload must match that pipeline’s Input schema).
path can be set in two ways in Model API:
- LoRA name from your LoRA Assets, e.g.
"path": "my_first_lora_3000.safetensors" - Public URL, e.g.
"path": "https://example.com/my_first_lora_3000.safetensors"
deployment_id), or want to choose hardware / autoscale, deploy it and use Serverless API (LoRA) instead of the Model API.