What is the Model API?
The Model API lets you run hosted models from RunComfy with a single, consistent REST interface:- No deployment (on-demand inference)
- Per-request billing
- Async queue: submit > get
request_id> poll status/result - Hosted outputs returned as URLs when the run completes
Choose a model
The Model API can run models/pipelines from two sources:Option A: Models catalog (hosted models)
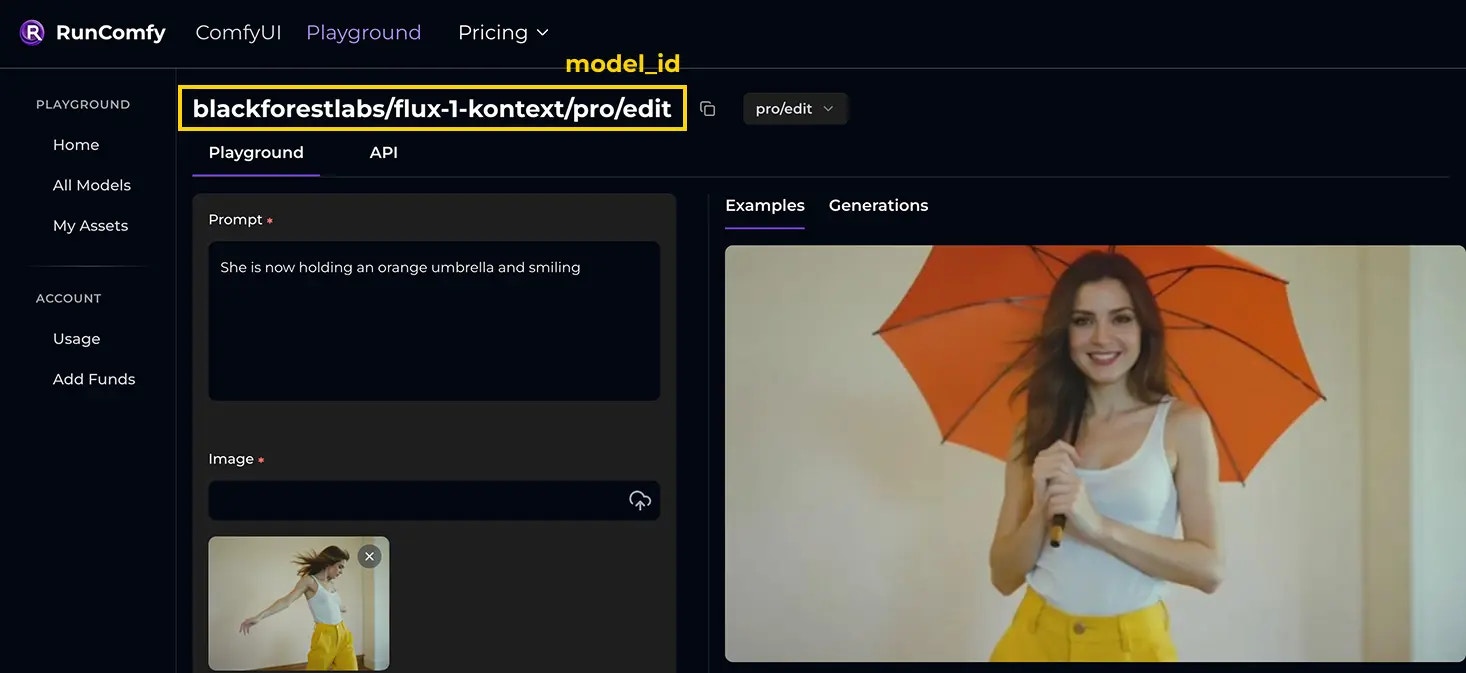
Pick a model from Models. Each model page shows itsmodel_id.
In this quickstart we’ll use:
blackforestlabs/flux-1-kontext/pro/edit
Its model_id is: blackforestlabs/flux-1-kontext/pro/edit
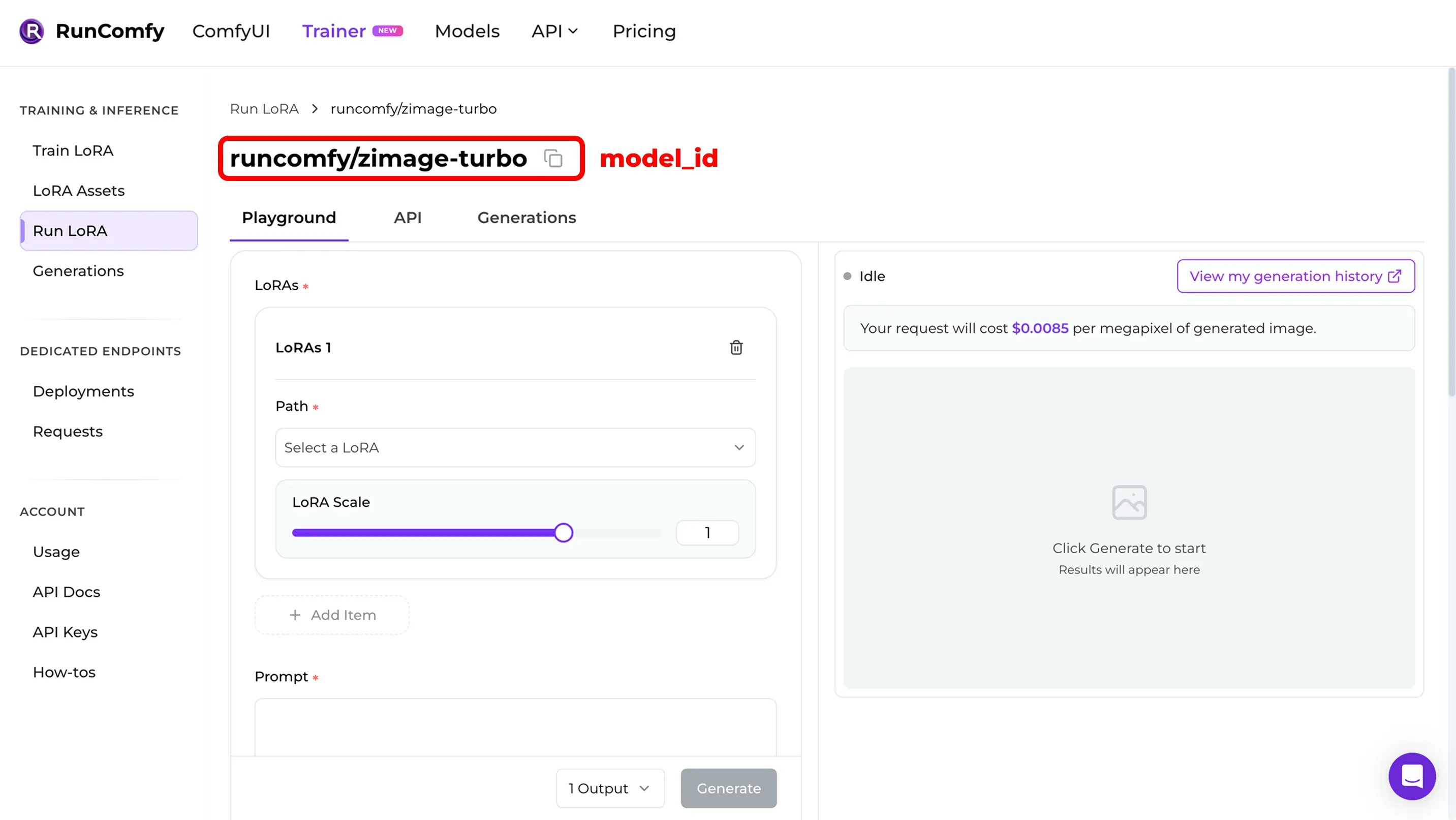
Option B: Trainer LoRA inference (on-demand)
If you trained (or imported) a LoRA in RunComfy Trainer and want to run inference without deploying, you can still use the Model API. Important detail:- you call a base model pipeline by
model_id - you pass the LoRA as input parameters in the request body
If you want a dedicated endpoint (choose hardware, autoscale, stable deployment_id), use Serverless API (LoRA).
Want to train a LoRA model yourself? Start with Trainer APIs Quickstart.
Authentication
All requests require a Bearer token:Authorization: Bearer <token>
Get your token from your Profile page.
Submit a request
Send a JSON body that matches the model’s input schema. For file inputs, provide publicly accessible HTTPS URLs.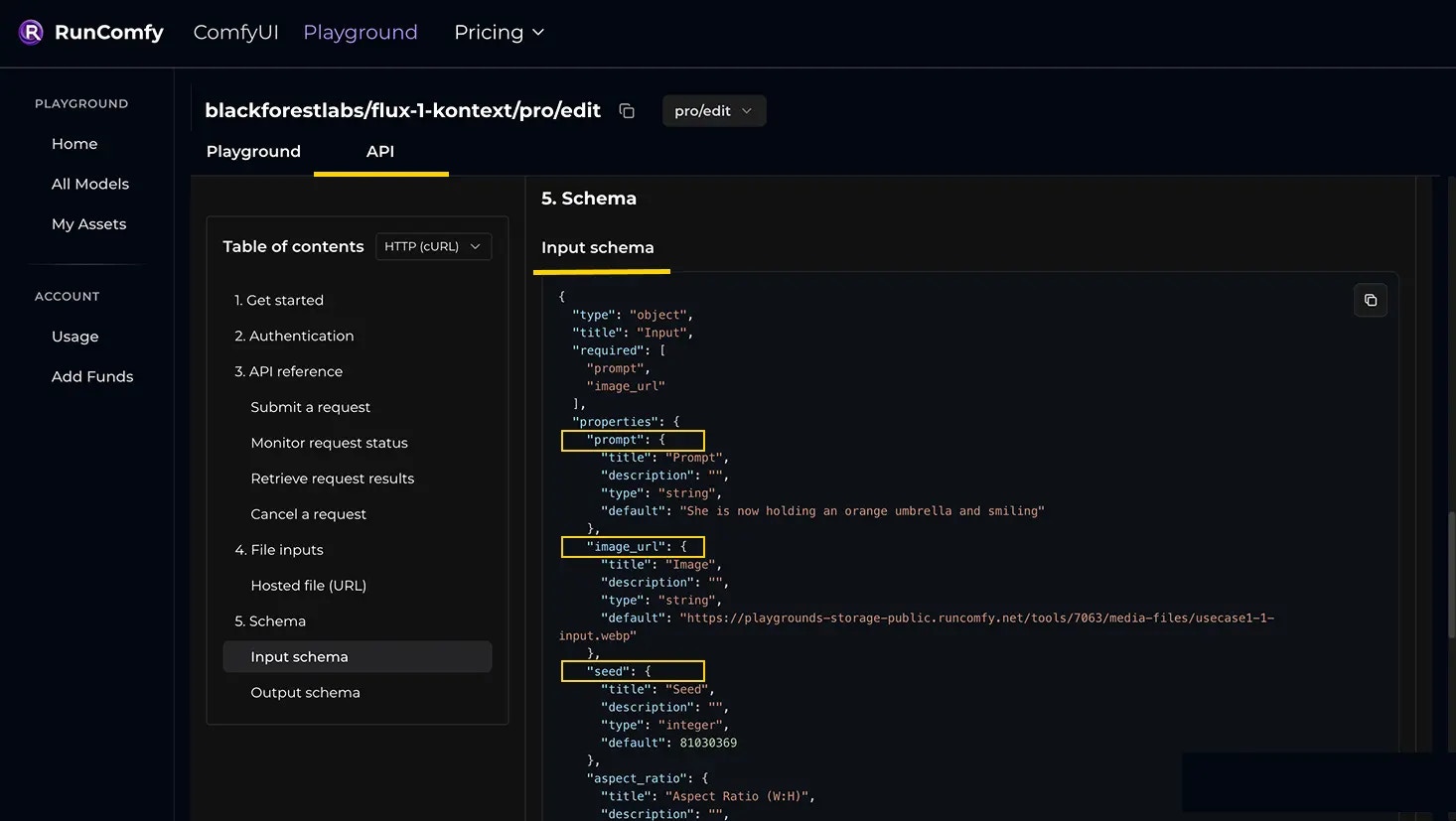
Poll status
in_queue > in_progress > completed