instance_id once the instance is active. With that ID, you can send authenticated requests through a proxy path to perform operational tasks such as unloading models or freeing GPU memory.
When to use the proxy
Start proxy calls once the request status is in_progress (after cold start) or completed, and you can readinstance_id from the Status endpoint:
Instance proxy endpoint
Base URL:https://api.runcomfy.net
Path parameters
deployment_id: string (required)instance_id: string (required)comfy_backend_path: string (required) — the target ComfyUI backend route, e.g.api/free
What you can call
The proxy forwards your request to the live instance. Common targets include:- ComfyUI backend endpoints (e.g.
GET /object_info,POST /api/prompt) - ComfyUI Manager endpoints (e.g.
POST /api/free)
Free memory / unload models
You can release GPU memory or unload models via ComfyUI Manager’s nativePOST /api/free endpoint. This can be useful in long-running sessions to ensure the next request starts from a clean state.
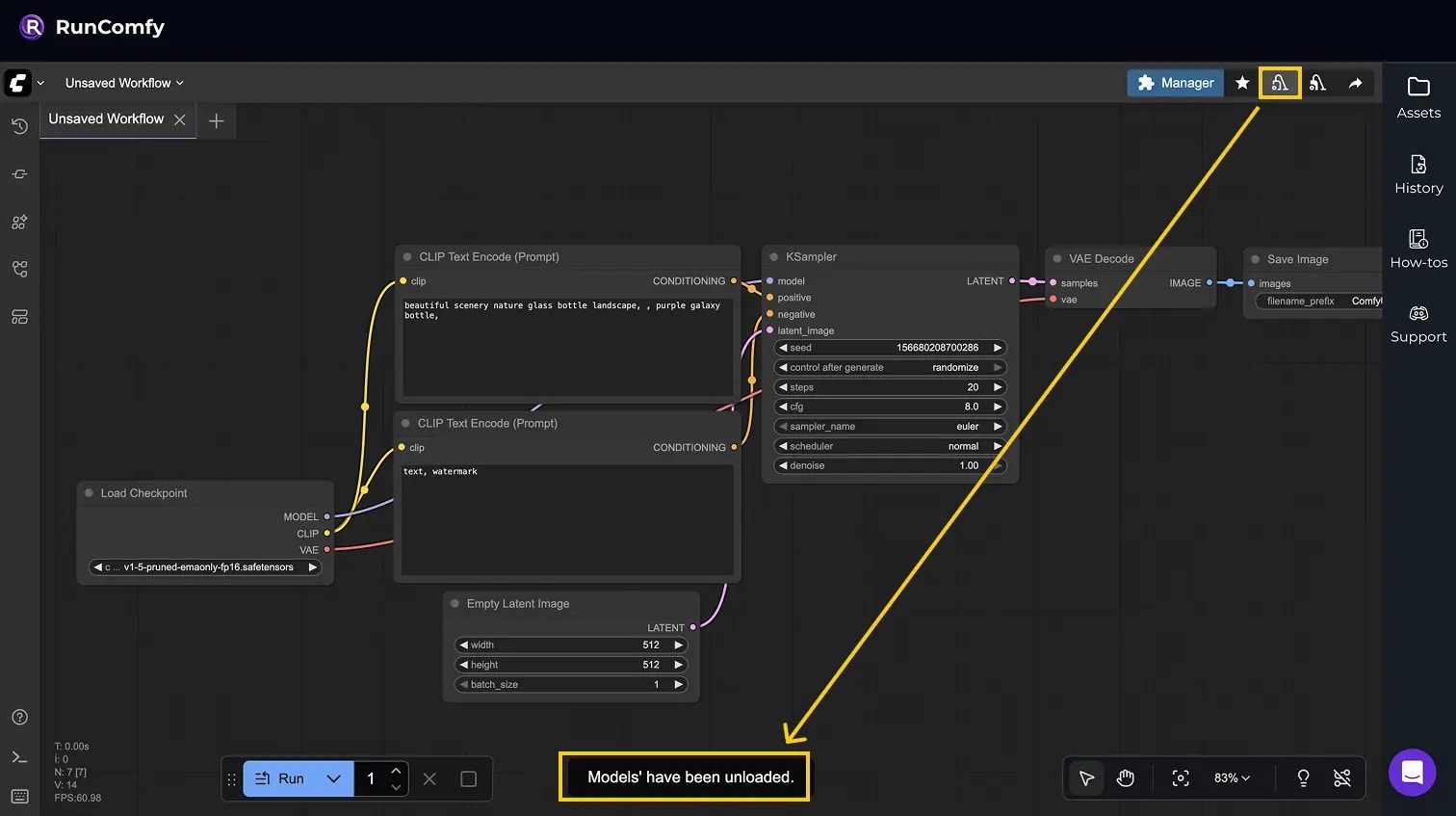
Request example: unload models only
Equivalent in the ComfyUI web UI: Manager → Unload models.
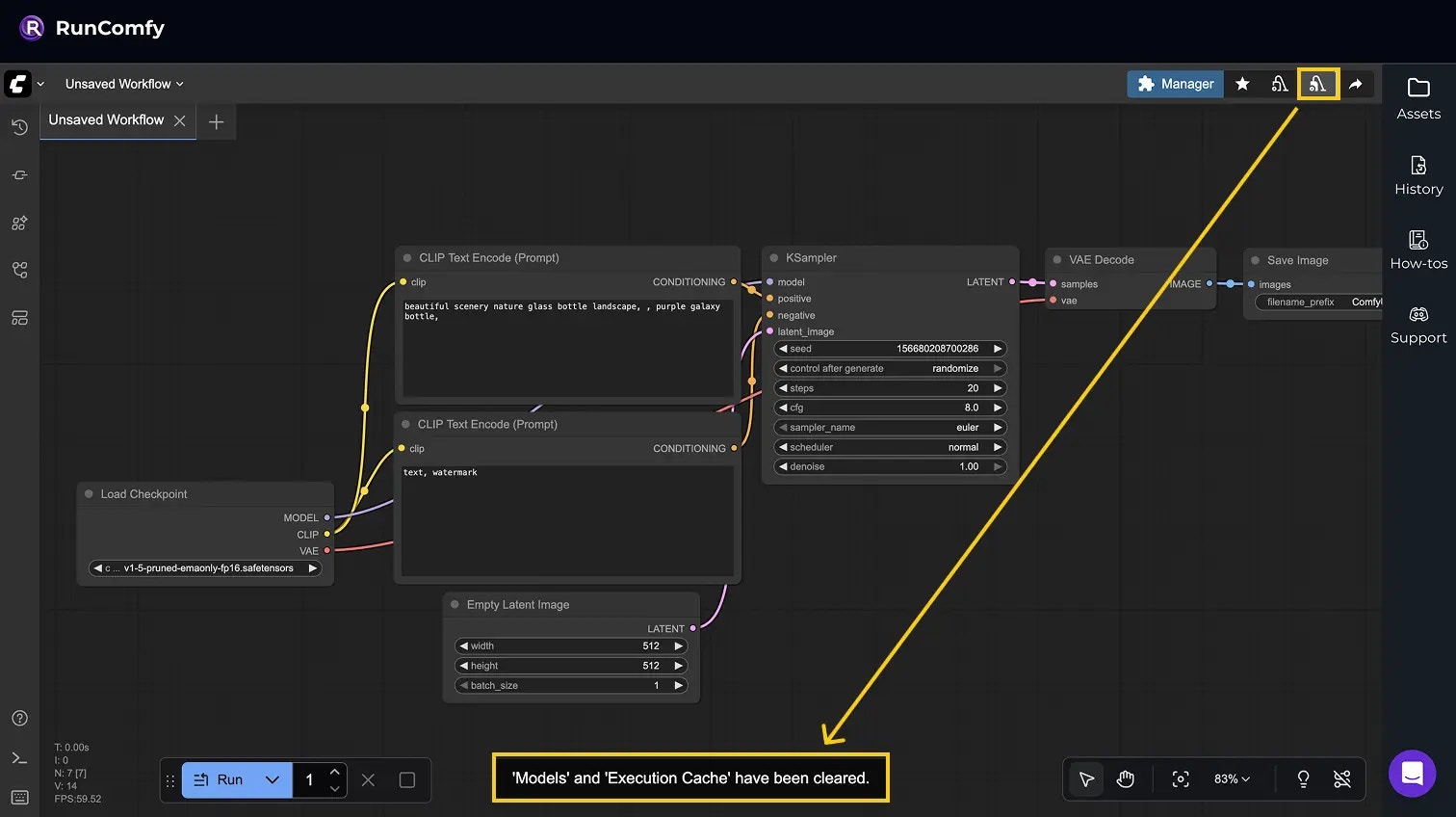
Request example: unload models and free memory
Equivalent in the ComfyUI web UI: Manager → Unload models and Clear execution cache (free memory).
Response example
Lifecycle notes and errors
- An
instance_idis valid only while its instance is running. If the instance shuts down due to keep-warm/idle timeout, subsequent proxy calls will fail. Submit a new job to start a fresh instance and obtain a newinstance_id. - Immediately after submitting a request, proxy calls may fail until the job status shows
in_progress(after cold start) orcompletedin the status endpoint. Poll status and retry once it transitions.